创建和操作字符串
Symfony 提供了一个面向对象的 API 来处理 Unicode 字符串(作为字节、代码点和字形簇)。此 API 通过 String 组件提供,您必须首先在您的应用程序中安装该组件
1
$ composer require symfony/string提示
如果您在 Symfony 应用程序之外安装此组件,您必须在代码中require vendor/autoload.php 文件,以启用 Composer 提供的类自动加载机制。阅读 本文 了解更多详情。
什么是字符串?
如果您已经知道“代码点”或“字形簇”在处理字符串的上下文中的含义,您可以跳过本节。否则,请阅读本节以了解此组件使用的术语。
像英语这样的语言只需要非常有限的字符和符号集就可以显示任何内容。每个字符串都是一系列字符(字母或符号),即使使用最有限的标准(例如 ASCII)也可以对其进行编码。
然而,其他语言需要数千个符号才能显示其内容。它们需要复杂的编码标准,例如 Unicode,并且“字符”之类的概念不再有意义。相反,您必须处理这些术语:
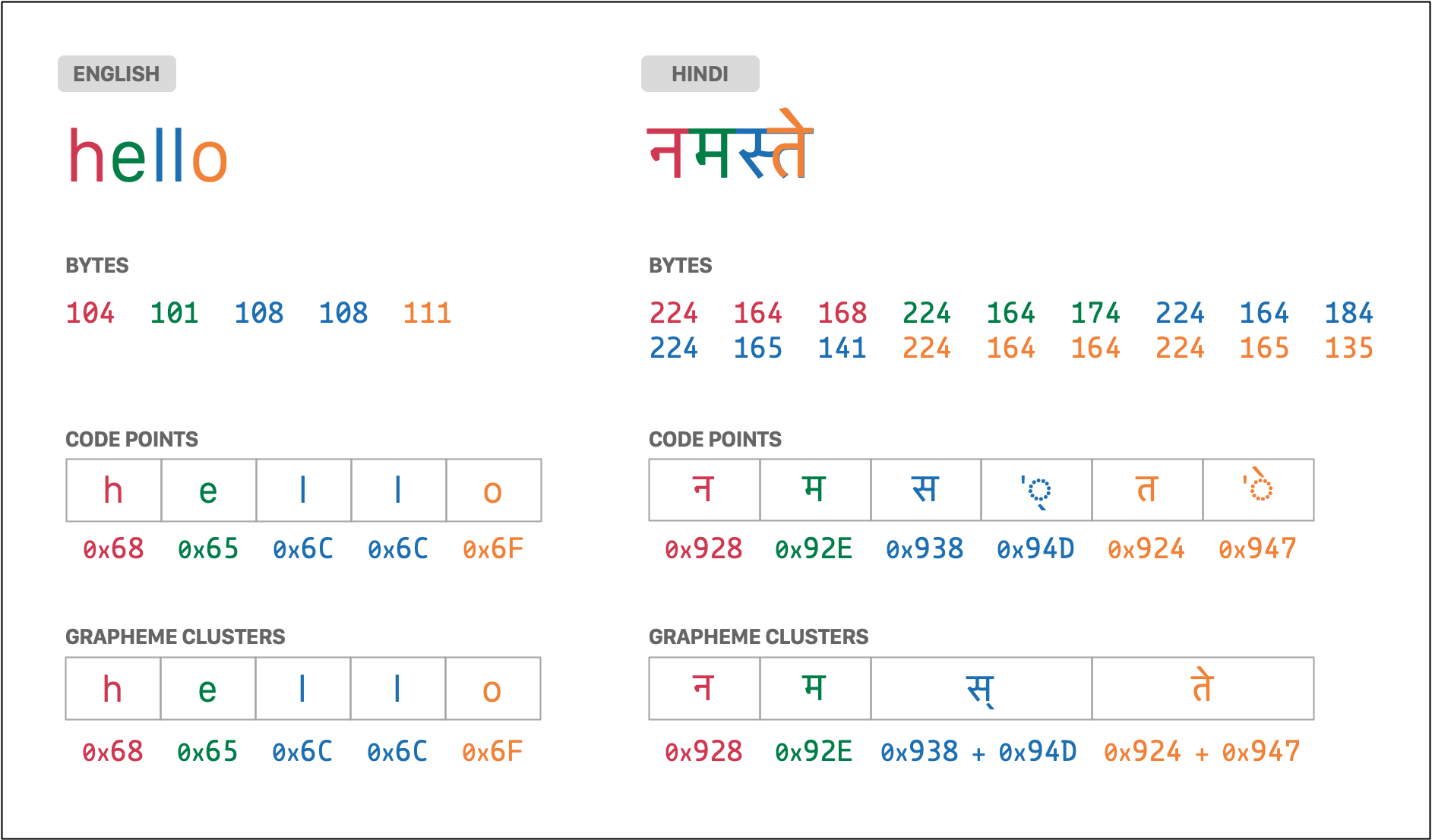
- 代码点:它们是信息的原子单位。字符串是一系列代码点。每个代码点都是一个数字,其含义由 Unicode 标准给出。例如,英文字母
A是U+0041代码点,日文假名の是U+306E代码点。 - 字形簇:它们是一个或多个代码点的序列,这些代码点显示为单个图形单元。例如,西班牙字母
ñ是一个字形簇,其中包含两个代码点:U+006E=n(“拉丁小写字母 N”)+U+0303=◌̃(“组合波浪号”)。 - 字节:它们是为字符串内容存储的实际信息。根据所使用的标准(UTF-8、UTF-16 等),每个代码点可能需要一个或多个字节的存储空间。
下图显示了用英语 (hello) 和印地语 (नमस्ते) 写的同一个词的字节、代码点和字形簇:
用法
创建一个 ByteString、CodePointString 或 UnicodeString 类型的新对象,将字符串内容作为其参数传递,然后使用面向对象的 API 来处理这些字符串:
1 2 3 4 5 6 7 8 9 10 11 12
use Symfony\Component\String\UnicodeString;
$text = (new UnicodeString('This is a déjà-vu situation.'))
->trimEnd('.')
->replace('déjà-vu', 'jamais-vu')
->append('!');
// $text = 'This is a jamais-vu situation!'
$content = new UnicodeString('नमस्ते दुनिया');
if ($content->ignoreCase()->startsWith('नमस्ते')) {
// ...
}方法参考
创建字符串对象的方法
首先,您可以创建准备好将字符串存储为字节、代码点和字形簇的对象,使用以下类:
1 2 3 4 5 6 7 8
use Symfony\Component\String\ByteString;
use Symfony\Component\String\CodePointString;
use Symfony\Component\String\UnicodeString;
$foo = new ByteString('hello');
$bar = new CodePointString('hello');
// UnicodeString is the most commonly used class
$baz = new UnicodeString('hello');使用 wrap() 静态方法来实例化多个字符串对象:
1 2 3 4 5 6 7
$contents = ByteString::wrap(['hello', 'world']); // $contents = ByteString[]
$contents = UnicodeString::wrap(['I', '❤️', 'Symfony']); // $contents = UnicodeString[]
// use the unwrap method to make the inverse conversion
$contents = UnicodeString::unwrap([
new UnicodeString('hello'), new UnicodeString('world'),
]); // $contents = ['hello', 'world']如果您使用大量的 String 对象,请考虑使用快捷函数,使您的代码更简洁:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
// the b() function creates byte strings
use function Symfony\Component\String\b;
// both lines are equivalent
$foo = new ByteString('hello');
$foo = b('hello');
// the u() function creates Unicode strings
use function Symfony\Component\String\u;
// both lines are equivalent
$foo = new UnicodeString('hello');
$foo = u('hello');
// the s() function creates a byte string or Unicode string
// depending on the given contents
use function Symfony\Component\String\s;
// creates a ByteString object
$foo = s("\xfe\xff");
// creates a UnicodeString object
$foo = s('अनुच्छेद');还有一些专门的构造函数:
1 2 3 4 5 6 7 8 9 10
// ByteString can create a random string of the given length
$foo = ByteString::fromRandom(12);
// by default, random strings use A-Za-z0-9 characters; you can restrict
// the characters to use with the second optional argument
$foo = ByteString::fromRandom(6, 'AEIOU0123456789');
$foo = ByteString::fromRandom(10, 'qwertyuiop');
// CodePointString and UnicodeString can create a string from code points
$foo = UnicodeString::fromCodePoints(0x928, 0x92E, 0x938, 0x94D, 0x924, 0x947);
// equivalent to: $foo = new UnicodeString('नमस्ते');转换字符串对象的方法
每个字符串对象都可以转换为其他两种类型的对象:
1 2 3 4 5 6 7 8
$foo = ByteString::fromRandom(12)->toCodePointString();
$foo = (new CodePointString('hello'))->toUnicodeString();
$foo = UnicodeString::fromCodePoints(0x68, 0x65, 0x6C, 0x6C, 0x6F)->toByteString();
// the optional $toEncoding argument defines the encoding of the target string
$foo = (new CodePointString('hello'))->toByteString('Windows-1252');
// the optional $fromEncoding argument defines the encoding of the original string
$foo = (new ByteString('さよなら'))->toCodePointString('ISO-2022-JP');如果由于任何原因无法转换,您将收到一个 InvalidArgumentException。
还有一个方法可以获取存储在某个位置的字节:
1 2 3 4 5 6 7
// ('नमस्ते' bytes = [224, 164, 168, 224, 164, 174, 224, 164, 184,
// 224, 165, 141, 224, 164, 164, 224, 165, 135])
b('नमस्ते')->bytesAt(0); // [224]
u('नमस्ते')->bytesAt(0); // [224, 164, 168]
b('नमस्ते')->bytesAt(1); // [164]
u('नमस्ते')->bytesAt(1); // [224, 164, 174]与长度和空白字符相关的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
// returns the number of graphemes, code points or bytes of the given string
$word = 'नमस्ते';
(new ByteString($word))->length(); // 18 (bytes)
(new CodePointString($word))->length(); // 6 (code points)
(new UnicodeString($word))->length(); // 4 (graphemes)
// some symbols require double the width of others to represent them when using
// a monospaced font (e.g. in a console). This method returns the total width
// needed to represent the entire word
$word = 'नमस्ते';
(new ByteString($word))->width(); // 18
(new CodePointString($word))->width(); // 4
(new UnicodeString($word))->width(); // 4
// if the text contains multiple lines, it returns the max width of all lines
$text = "<<<END
This is a
multiline text
END";
u($text)->width(); // 14
// only returns TRUE if the string is exactly an empty string (not even whitespace)
u('hello world')->isEmpty(); // false
u(' ')->isEmpty(); // false
u('')->isEmpty(); // true
// removes all whitespace (' \n\r\t\x0C') from the start and end of the string and
// replaces two or more consecutive whitespace characters with a single space (' ') character
u(" \n\n hello \t \n\r world \n \n")->collapseWhitespace(); // 'hello world'更改大小写的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34
// changes all graphemes/code points to lower case
u('FOO Bar Brİan')->lower(); // 'foo bar bri̇an'
// changes all graphemes/code points to lower case according to locale-specific case mappings
u('FOO Bar Brİan')->localeLower('en'); // 'foo bar bri̇an'
u('FOO Bar Brİan')->localeLower('lt'); // 'foo bar bri̇̇an'
// when dealing with different languages, uppercase/lowercase is not enough
// there are three cases (lower, upper, title), some characters have no case,
// case is context-sensitive and locale-sensitive, etc.
// this method returns a string that you can use in case-insensitive comparisons
u('FOO Bar')->folded(); // 'foo bar'
u('Die O\'Brian Straße')->folded(); // "die o'brian strasse"
// changes all graphemes/code points to upper case
u('foo BAR bάz')->upper(); // 'FOO BAR BΆZ'
// changes all graphemes/code points to upper case according to locale-specific case mappings
u('foo BAR bάz')->localeUpper('en'); // 'FOO BAR BΆZ'
u('foo BAR bάz')->localeUpper('el'); // 'FOO BAR BAZ'
// changes all graphemes/code points to "title case"
u('foo ijssel')->title(); // 'Foo ijssel'
u('foo ijssel')->title(allWords: true); // 'Foo Ijssel'
// changes all graphemes/code points to "title case" according to locale-specific case mappings
u('foo ijssel')->localeTitle('en'); // 'Foo ijssel'
u('foo ijssel')->localeTitle('nl'); // 'Foo IJssel'
// changes all graphemes/code points to camelCase
u('Foo: Bar-baz.')->camel(); // 'fooBarBaz'
// changes all graphemes/code points to snake_case
u('Foo: Bar-baz.')->snake(); // 'foo_bar_baz'
// changes all graphemes/code points to kebab-case
u('Foo: Bar-baz.')->kebab(); // 'foo-bar-baz'
// other cases can be achieved by chaining methods. E.g. PascalCase:
u('Foo: Bar-baz.')->camel()->title(); // 'FooBarBaz'7.1
localeLower()、localeUpper() 和 localeTitle() 方法是在 Symfony 7.1 中引入的。
7.2
kebab() 方法是在 Symfony 7.2 中引入的。
默认情况下,所有字符串类的方法都区分大小写。您可以使用 ignoreCase() 方法执行不区分大小写的操作:
1 2
u('abc')->indexOf('B'); // null
u('abc')->ignoreCase()->indexOf('B'); // 1追加和前置方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32
// adds the given content (one or more strings) at the beginning/end of the string
u('world')->prepend('hello'); // 'helloworld'
u('world')->prepend('hello', ' '); // 'hello world'
u('hello')->append('world'); // 'helloworld'
u('hello')->append(' ', 'world'); // 'hello world'
// adds the given content at the beginning of the string (or removes it) to
// make sure that the content starts exactly with that content
u('Name')->ensureStart('get'); // 'getName'
u('getName')->ensureStart('get'); // 'getName'
u('getgetName')->ensureStart('get'); // 'getName'
// this method is similar, but works on the end of the content instead of on the beginning
u('User')->ensureEnd('Controller'); // 'UserController'
u('UserController')->ensureEnd('Controller'); // 'UserController'
u('UserControllerController')->ensureEnd('Controller'); // 'UserController'
// returns the contents found before/after the first occurrence of the given string
u('hello world')->before('world'); // 'hello '
u('hello world')->before('o'); // 'hell'
u('hello world')->before('o', includeNeedle: true); // 'hello'
u('hello world')->after('hello'); // ' world'
u('hello world')->after('o'); // ' world'
u('hello world')->after('o', includeNeedle: true); // 'o world'
// returns the contents found before/after the last occurrence of the given string
u('hello world')->beforeLast('o'); // 'hello w'
u('hello world')->beforeLast('o', includeNeedle: true); // 'hello wo'
u('hello world')->afterLast('o'); // 'rld'
u('hello world')->afterLast('o', includeNeedle: true); // 'orld'填充和修剪方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
// makes a string as long as the first argument by adding the given
// string at the beginning, end or both sides of the string
u(' Lorem Ipsum ')->padBoth(20, '-'); // '--- Lorem Ipsum ----'
u(' Lorem Ipsum')->padStart(20, '-'); // '-------- Lorem Ipsum'
u('Lorem Ipsum ')->padEnd(20, '-'); // 'Lorem Ipsum --------'
// repeats the given string the number of times passed as argument
u('_.')->repeat(10); // '_._._._._._._._._._.'
// removes the given characters (default: whitespace characters) from the beginning and end of a string
u(' Lorem Ipsum ')->trim(); // 'Lorem Ipsum'
u('Lorem Ipsum ')->trim('m'); // 'Lorem Ipsum '
u('Lorem Ipsum')->trim('m'); // 'Lorem Ipsu'
u(' Lorem Ipsum ')->trimStart(); // 'Lorem Ipsum '
u(' Lorem Ipsum ')->trimEnd(); // ' Lorem Ipsum'
// removes the given content from the start/end of the string
u('file-image-0001.png')->trimPrefix('file-'); // 'image-0001.png'
u('file-image-0001.png')->trimPrefix('image-'); // 'file-image-0001.png'
u('file-image-0001.png')->trimPrefix('file-image-'); // '0001.png'
u('template.html.twig')->trimSuffix('.html'); // 'template.html.twig'
u('template.html.twig')->trimSuffix('.twig'); // 'template.html'
u('template.html.twig')->trimSuffix('.html.twig'); // 'template'
// when passing an array of prefix/suffix, only the first one found is trimmed
u('file-image-0001.png')->trimPrefix(['file-', 'image-']); // 'image-0001.png'
u('template.html.twig')->trimSuffix(['.twig', '.html']); // 'template.html'搜索和替换方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
// checks if the string starts/ends with the given string
u('https://symfony.ac.cn')->startsWith('https'); // true
u('report-1234.pdf')->endsWith('.pdf'); // true
// checks if the string contents are exactly the same as the given contents
u('foo')->equalsTo('foo'); // true
// checks if the string content match the given regular expression.
u('avatar-73647.png')->match('/avatar-(\d+)\.png/');
// result = ['avatar-73647.png', '73647', null]
// You can pass flags for preg_match() as second argument. If PREG_PATTERN_ORDER
// or PREG_SET_ORDER are passed, preg_match_all() will be used.
u('206-555-0100 and 800-555-1212')->match('/\d{3}-\d{3}-\d{4}/', \PREG_PATTERN_ORDER);
// result = [['206-555-0100', '800-555-1212']]
// checks if the string contains any of the other given strings
u('aeiou')->containsAny('a'); // true
u('aeiou')->containsAny(['ab', 'efg']); // false
u('aeiou')->containsAny(['eio', 'foo', 'z']); // true
// finds the position of the first occurrence of the given string
// (the second argument is the position where the search starts and negative
// values have the same meaning as in PHP functions)
u('abcdeabcde')->indexOf('c'); // 2
u('abcdeabcde')->indexOf('c', 2); // 2
u('abcdeabcde')->indexOf('c', -4); // 7
u('abcdeabcde')->indexOf('eab'); // 4
u('abcdeabcde')->indexOf('k'); // null
// finds the position of the last occurrence of the given string
// (the second argument is the position where the search starts and negative
// values have the same meaning as in PHP functions)
u('abcdeabcde')->indexOfLast('c'); // 7
u('abcdeabcde')->indexOfLast('c', 2); // 7
u('abcdeabcde')->indexOfLast('c', -4); // 2
u('abcdeabcde')->indexOfLast('eab'); // 4
u('abcdeabcde')->indexOfLast('k'); // null
// replaces all occurrences of the given string
u('https://symfony.ac.cn')->replace('http://', 'https://'); // 'https://symfony.ac.cn'
// replaces all occurrences of the given regular expression
u('(+1) 206-555-0100')->replaceMatches('/[^A-Za-z0-9]++/', ''); // '12065550100'
// you can pass a callable as the second argument to perform advanced replacements
u('123')->replaceMatches('/\d/', function (string $match): string {
return '['.$match[0].']';
}); // result = '[1][2][3]'连接、拆分、截断和反转方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
// uses the string as the "glue" to merge all the given strings
u(', ')->join(['foo', 'bar']); // 'foo, bar'
// breaks the string into pieces using the given delimiter
u('template_name.html.twig')->split('.'); // ['template_name', 'html', 'twig']
// you can set the maximum number of pieces as the second argument
u('template_name.html.twig')->split('.', 2); // ['template_name', 'html.twig']
// returns a substring which starts at the first argument and has the length of the
// second optional argument (negative values have the same meaning as in PHP functions)
u('Symfony is great')->slice(0, 7); // 'Symfony'
u('Symfony is great')->slice(0, -6); // 'Symfony is'
u('Symfony is great')->slice(11); // 'great'
u('Symfony is great')->slice(-5); // 'great'
// reduces the string to the length given as argument (if it's longer)
u('Lorem Ipsum')->truncate(3); // 'Lor'
u('Lorem Ipsum')->truncate(80); // 'Lorem Ipsum'
// the second argument is the character(s) added when a string is cut
// (the total length includes the length of this character(s))
// (note that '…' is a single character that includes three dots; it's not '...')
u('Lorem Ipsum')->truncate(8, '…'); // 'Lorem I…'
// the third optional argument defines how to cut words when the length is exceeded
// the default value is TruncateMode::Char which cuts the string at the exact given length
u('Lorem ipsum dolor sit amet')->truncate(8, cut: TruncateMode::Char); // 'Lorem ip'
// returns up to the last complete word that fits in the given length without surpassing it
u('Lorem ipsum dolor sit amet')->truncate(8, cut: TruncateMode::WordBefore); // 'Lorem'
// returns up to the last complete word that fits in the given length, surpassing it if needed
u('Lorem ipsum dolor sit amet')->truncate(8, cut: TruncateMode::WordAfter); // 'Lorem ipsum'7.2
truncate 函数的 TruncateMode 参数是在 Symfony 7.2 中引入的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
// breaks the string into lines of the given length
u('Lorem Ipsum')->wordwrap(4); // 'Lorem\nIpsum'
// by default it breaks by white space; pass TRUE to break unconditionally
u('Lorem Ipsum')->wordwrap(4, "\n", cut: true); // 'Lore\nm\nIpsu\nm'
// replaces a portion of the string with the given contents:
// the second argument is the position where the replacement starts;
// the third argument is the number of graphemes/code points removed from the string
u('0123456789')->splice('xxx'); // 'xxx'
u('0123456789')->splice('xxx', 0, 2); // 'xxx23456789'
u('0123456789')->splice('xxx', 0, 6); // 'xxx6789'
u('0123456789')->splice('xxx', 6); // '012345xxx'
// breaks the string into pieces of the length given as argument
u('0123456789')->chunk(3); // ['012', '345', '678', '9']
// reverses the order of the string contents
u('foo bar')->reverse(); // 'rab oof'
u('さよなら')->reverse(); // 'らなよさ'ByteString 添加的方法
这些方法仅适用于 ByteString 对象:
1 2 3
// returns TRUE if the string contents are valid UTF-8 contents
b('Lorem Ipsum')->isUtf8(); // true
b("\xc3\x28")->isUtf8(); // falseCodePointString 和 UnicodeString 添加的方法
这些方法仅适用于 CodePointString 和 UnicodeString 对象:
1 2 3 4 5 6 7 8 9 10 11
// transliterates any string into the latin alphabet defined by the ASCII encoding
// (don't use this method to build a slugger because this component already provides
// a slugger, as explained later in this article)
u('नमस्ते')->ascii(); // 'namaste'
u('さよなら')->ascii(); // 'sayonara'
u('спасибо')->ascii(); // 'spasibo'
// returns an array with the code point or points stored at the given position
// (code points of 'नमस्ते' graphemes = [2344, 2350, 2360, 2340]
u('नमस्ते')->codePointsAt(0); // [2344]
u('नमस्ते')->codePointsAt(2); // [2360]Unicode 等价性是 Unicode 标准对不同代码点序列表示相同字符的规范。例如,瑞典字母 å 可以是单个代码点 (U+00E5 = “带圈的拉丁小写字母 A”) 或两个代码点的序列 (U+0061 = “拉丁小写字母 A” + U+030A = “组合圈”)。normalize() 方法允许选择规范化模式:
1 2 3 4 5 6
// these encode the letter as a single code point: U+00E5
u('å')->normalize(UnicodeString::NFC);
u('å')->normalize(UnicodeString::NFKC);
// these encode the letter as two code points: U+0061 + U+030A
u('å')->normalize(UnicodeString::NFD);
u('å')->normalize(UnicodeString::NFKD);延迟加载字符串
有时,使用前面章节中介绍的方法创建字符串不是最佳的。例如,考虑一个哈希值,它需要一定的计算才能获得,而您最终可能不会使用它。
在这些情况下,最好使用 LazyString 类,该类允许存储一个字符串,其值仅在您需要时才生成:
1 2 3 4 5 6 7 8 9
use Symfony\Component\String\LazyString;
$lazyString = LazyString::fromCallable(function (): string {
// Compute the string value...
$value = ...;
// Then return the final value
return $value;
});回调函数仅在程序执行期间请求延迟字符串的值时执行。您还可以从 Stringable 对象创建延迟字符串:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
class Hash implements \Stringable
{
public function __toString(): string
{
return $this->computeHash();
}
private function computeHash(): string
{
// Compute hash value with potentially heavy processing
$hash = ...;
return $hash;
}
}
// Then create a lazy string from this hash, which will trigger
// hash computation only if it's needed
$lazyHash = LazyString::fromStringable(new Hash());使用表情符号
这些内容已移至 Emoji 组件文档。
Slugger
在某些上下文中,例如 URL 和文件/目录名称,使用任何 Unicode 字符都是不安全的。slugger 将给定的字符串转换为另一个仅包含安全 ASCII 字符的字符串:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
use Symfony\Component\String\Slugger\AsciiSlugger;
$slugger = new AsciiSlugger();
$slug = $slugger->slug('Wôrķšƥáçè ~~sèťtïñğš~~');
// $slug = 'Workspace-settings'
// you can also pass an array with additional character substitutions
$slugger = new AsciiSlugger('en', ['en' => ['%' => 'percent', '€' => 'euro']]);
$slug = $slugger->slug('10% or 5€');
// $slug = '10-percent-or-5-euro'
// if there is no symbols map for your locale (e.g. 'en_GB') then the parent locale's symbols map
// will be used instead (i.e. 'en')
$slugger = new AsciiSlugger('en_GB', ['en' => ['%' => 'percent', '€' => 'euro']]);
$slug = $slugger->slug('10% or 5€');
// $slug = '10-percent-or-5-euro'
// for more dynamic substitutions, pass a PHP closure instead of an array
$slugger = new AsciiSlugger('en', function (string $string, string $locale): string {
return str_replace('❤️', 'love', $string);
});单词之间的分隔符默认为破折号 (-),但您可以将另一个分隔符定义为第二个参数:
1 2
$slug = $slugger->slug('Wôrķšƥáçè ~~sèťtïñğš~~', '/');
// $slug = 'Workspace/settings'slugger 在应用其他转换之前,会将原始字符串音译为拉丁文字。原始字符串的语言环境会自动检测,但您可以显式定义它:
1 2 3 4 5 6
// this tells the slugger to transliterate from Korean ('ko') language
$slugger = new AsciiSlugger('ko');
// you can override the locale as the third optional parameter of slug()
// e.g. this slugger transliterates from Persian ('fa') language
$slug = $slugger->slug('...', '-', 'fa');在 Symfony 应用程序中,您不需要自己创建 slugger。感谢 服务自动装配,您可以通过使用 SluggerInterface 类型提示服务构造函数参数来注入 slugger。注入的 slugger 的语言环境与请求语言环境相同:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
use Symfony\Component\String\Slugger\SluggerInterface;
class MyService
{
public function __construct(
private SluggerInterface $slugger,
) {
}
public function someMethod(): void
{
$slug = $this->slugger->slug('...');
}
}Slug 表情符号
您还可以将 emoji 音译器与 slugger 结合使用,以将任何表情符号转换为其文本表示形式:
1 2 3 4 5 6 7 8 9 10
use Symfony\Component\String\Slugger\AsciiSlugger;
$slugger = new AsciiSlugger();
$slugger = $slugger->withEmoji();
$slug = $slugger->slug('a 😺, 🐈⬛, and a 🦁 go to 🏞️', '-', 'en');
// $slug = 'a-grinning-cat-black-cat-and-a-lion-go-to-national-park';
$slug = $slugger->slug('un 😺, 🐈⬛, et un 🦁 vont au 🏞️', '-', 'fr');
// $slug = 'un-chat-qui-sourit-chat-noir-et-un-tete-de-lion-vont-au-parc-national';如果您想为表情符号使用特定的语言环境,或者使用来自 GitHub、Gitlab 或 Slack 的短代码,请使用 withEmoji() 方法的第一个参数:
1 2 3 4 5 6 7
use Symfony\Component\String\Slugger\AsciiSlugger;
$slugger = new AsciiSlugger();
$slugger = $slugger->withEmoji('github'); // or "en", or "fr", etc.
$slug = $slugger->slug('a 😺, 🐈⬛, and a 🦁');
// $slug = 'a-smiley-cat-black-cat-and-a-lion';Inflector
在某些场景下,例如代码生成和代码内省,您需要将单词从单数/复数形式相互转换。例如,要了解与 adder 方法关联的属性,您必须从复数形式(addStories() 方法)转换为单数形式($story 属性)。
大多数人类语言都有简单的复数规则,但同时它们也定义了许多例外。例如,英语中的一般规则是在单词末尾添加 s (book -> books),但即使对于常用词也存在很多例外 (woman -> women、life -> lives、news -> news、radius -> radii 等等)。
此组件提供了一个 EnglishInflector 类,用于自信地将英语单词从单数/复数形式相互转换:
1 2 3 4 5 6 7 8 9 10 11
use Symfony\Component\String\Inflector\EnglishInflector;
$inflector = new EnglishInflector();
$result = $inflector->singularize('teeth'); // ['tooth']
$result = $inflector->singularize('radii'); // ['radius']
$result = $inflector->singularize('leaves'); // ['leaf', 'leave', 'leaff']
$result = $inflector->pluralize('bacterium'); // ['bacteria']
$result = $inflector->pluralize('news'); // ['news']
$result = $inflector->pluralize('person'); // ['persons', 'people']两种方法返回的值始终是一个数组,因为有时不可能为给定的单词确定唯一的单数/复数形式。
Symfony 还为其他语言提供了 inflection 工具:
1 2 3 4 5 6 7 8 9 10 11
use Symfony\Component\String\Inflector\FrenchInflector;
$inflector = new FrenchInflector();
$result = $inflector->singularize('souris'); // ['souris']
$result = $inflector->pluralize('hôpital'); // ['hôpitaux']
use Symfony\Component\String\Inflector\SpanishInflector;
$inflector = new SpanishInflector();
$result = $inflector->singularize('aviones'); // ['avión']
$result = $inflector->pluralize('miércoles'); // ['miércoles']7.2
SpanishInflector 类是在 Symfony 7.2 中引入的。
提示
如果您需要实现自己的 inflection 工具,Symfony 提供了 InflectorInterface。